Hardware Abstractions
CIMFlow's three-level hardware abstraction hierarchy for SRAM-based Compute-in-Memory architectures
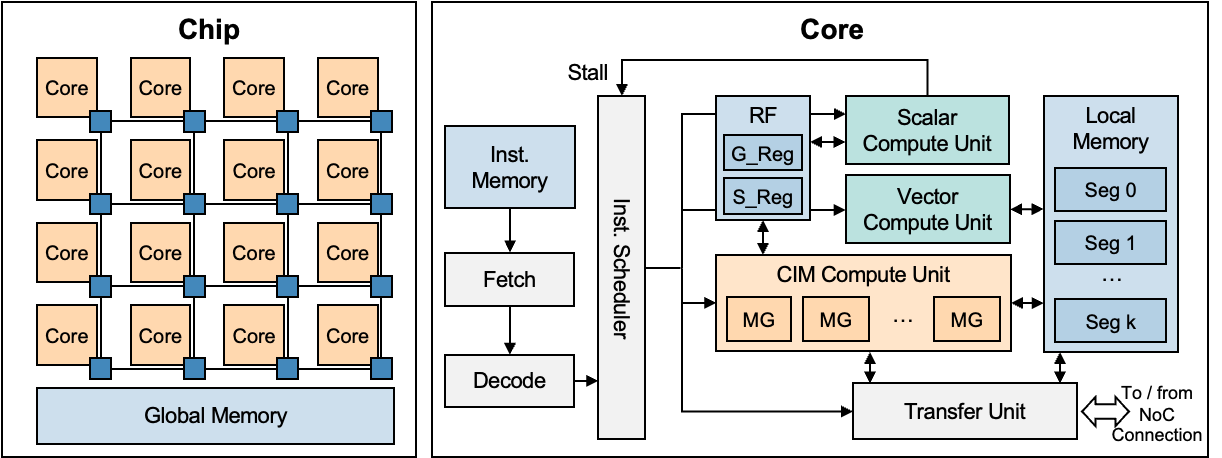
CIMFlow organizes CIM accelerator hardware into three abstraction levels: Chip, Core, and Unit. Each level corresponds to stages in the compilation and simulation pipeline.
Chip Level
The chip level describes the top-level organization of a multi-core CIM accelerator, including how cores communicate and share resources.
Network-on-Chip (NoC)
Cores and shared resources connect through an on-chip network, such as a 2D mesh. The NoC handles data exchange between cores and provides access to global shared memory.
Global Memory
A shared memory stores neural network weights, feature maps, activations, and intermediate results accessible by all cores.
Synchronous Inter-Core Communication: Transfers between cores are blocking. A core waits until the transfer completes before continuing execution.
Core Level
Each core has its own compute units, local memory, and register files.
Components
Memory
Global and local memories share a unified address space. Local memory uses a segmented layout with dedicated regions for input and output data.
Registers
GRFGeneralSRFSpecialUnit Level
Each core contains three types of compute units:
CIM Compute Unit
The CIM unit performs matrix-vector multiplication (MVM) in SRAM arrays. It contains K macro groups, each with T macros (both are architecture parameters).
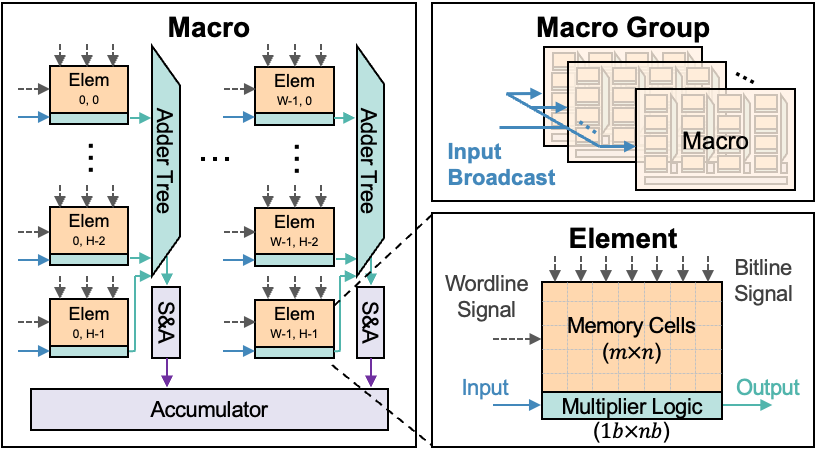
Each macro group operates independently for data parallelism. Macros within a group share input data but store different weights, organized along the output channel dimension.
Vector Compute Unit
The vector unit handles element-wise operations after MVM: quantization, activation functions (ReLU, Sigmoid, Tanh), partial sum accumulation, residual addition, and pooling.
Scalar Compute Unit
The scalar unit handles control flow and address generation: computing load/store addresses, conditional and unconditional branches, loop counters, and barrier-based synchronization for multi-core coordination.
Last updated on